[Mysql][转发]MySQL 索引合并优化实践
在生产环境的数据库中,经常会看到有些 SQL 的 where 条件包含:普通索引等值 + 主键范围查询 + order by limit。明明走普通索引效率更高,但是选择走了索引合并,本文就对这种索引合并的情况研究一下。
作者:张洛丹,热衷于数据库技术,不断探索,期望未来能够撰写更有深度的文章,输出更有价值的内容!
前言
在生产环境的数据库中,经常会看到有些 SQL 的 where 条件包含:普通索引等值 + 主键范围查询 + order by limit。明明走普通索引效率更高,但是选择走了索引合并,本文就对这种索引合并的情况研究一下。
Index Merge 官方介绍
The Index Merge access method retrieves rows with multiple range scans and merges their results into one.
一般对于一个单表,优化器选择一个索引,但在索引合并的情况下,优化器可以使用多个索引来获取数据并对其结果进行合并。
注意:这里实际上是先通过二级索引获取到主键,对主键进行排序合并,然后根据主键回表,来避免随机 IO。
归并排序算法
在介绍索引合并的方式及算法前,先来简单看下归并排序算法,以可以更好地理解 MySQL 中的索引合并。
归并算法是分治思想的应用,递归地将列表分成更小的子列表,将子列表进行排序,然后合并来得到有序列表。
参考阅读:图解归并排序
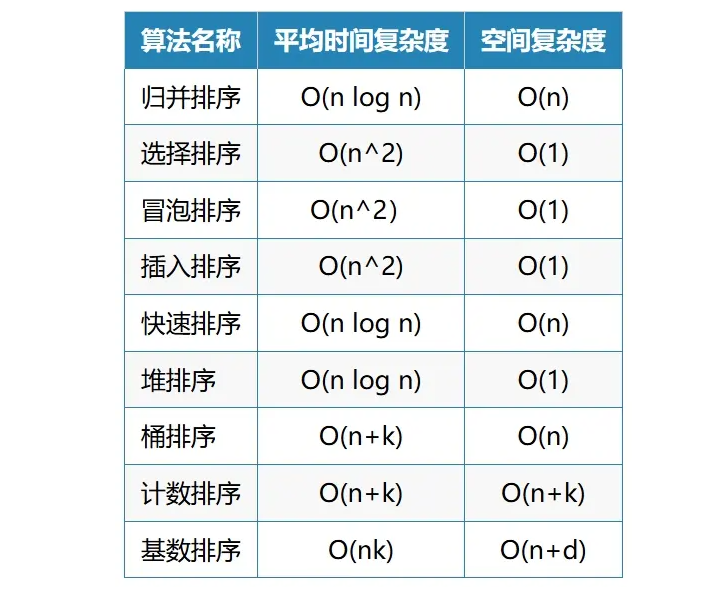
下面是几种常见算法的时间复杂度:可以看到归并排序还是比较快的。
MySQL 中的索引合并
在 MySQL 中,索引合并算法有下面几种:
index_merge_intersection:交集,对应执行计划
Extra:Using intersect(...),对应源码中的QUICK_ROR_INTERSECT_SELECT类。index_merge_union:并集,对应执行计划
Extra:Using union(...),对应源码中的QUICK_ROR_UNION_SELECT类。index_merge_sort_union:有序并集,对应执行计划
Extra:Using sort_union(...),对应源码中的QUICK_INDEX_MERGE_SELECT类。
这里可以看到在前两种方式中,实现类名都有 ROR 关键字。ROR 的含义是 Rowid-Ordered Retrieval,表示单个索引返回的结果集是按照主键有序排列的。根据归并排序算法,进行合并结果集的时候就省去了递归排序的步骤,而只需要将有序列表合并即可。
而对于第三种方式,由于返回的结果不是按照主键排序的,则需要先进行归并排序。
对于前两种情况,在下面条件返回的结果集主键是有序的,则其 where 条件需要满足下面的条件:
二级索引的条件满足:where 条件需要有所有的索引字段,且是等值匹配。例如一个索引
idx(a,b,c),则使用该索引的 where 条件需要是:a=? and b=? and c=?。主键范围查询
其中,用到交集(intersection)算法的,通常是用 and 连接的各索引条件,经过索引合并后的主键结果集,比走一个索引的主键结果集更小的情况下比较有优势;使用到并集(union)算法的,通常是 or 连接的各部分条件,走两个索引比走全表扫描成本更低的情况下有优势。
而对于第三种情况,在不能使用前两种算法的情况下,如果经过计算走索引合并的成本更低,会选择,该种算法需要去重和排序,这里去重和排序使用到树结构,强行去扒了一点点源码,放在这里。
sql opt_range.cc
int QUICK_INDEX_MERGE_SELECT::read_keys_and_merge()
-- 该函数的作用是:
在索引合并中,扫描使用到的所有索引(除了CPK-Clustered Primary key,即主键)并将其rowid合并
如果某个记录能从主键范围条件中扫描获取到,则跳过该行
否则后续执行unique_add方法,该方法向树结构中插入元素,实现了排序和去重
/* skip row if it will be retrieved by clustered PK scan */
if (pk_quick_select && pk_quick_select->row_in_ranges())
continue;
cur_quick->file->position(cur_quick->record);
result= unique->unique_add((char*)cur_quick->file->ref);
if (result)
DBUG_RETURN(1);
unique_add方法,在其中调用了tree_insert
inline bool unique_add(void *ptr)
{
DBUG_ENTER("unique_add");
DBUG_PRINT("info", ("tree %u - %lu", tree.elements_in_tree, max_elements));
if (tree.elements_in_tree > max_elements && flush())
DBUG_RETURN(1);
DBUG_RETURN(!tree_insert(&tree, ptr, 0, tree.custom_arg));
}
-- tree_insert中,在遍历树的过程中,有一行代码,
如下:表示如果不是树的null节点,则进行比较元素是否和要插入的值相等,相等则跳出循环(这样也就保证了树上不会有重复的值)
for (;;)
{
if (element == &tree->null_element ||
(cmp = (*tree->compare)(custom_arg, ELEMENT_KEY(tree,element),
key)) == 0)
break;
...综上,以下三种算法的示例 SQL:
-- 可用到 index_merge_intersection/index_merge_union 算法
SELECT * FROM innodb_table
WHERE primary_key < 10 AND/OR key1 = 20;
SELECT * FROM innodb_table
WHERE (key1_part1 = 1 AND key1_part2 = 2) AND/OR key2 = 2;
-- 可用到 index_merge_sort_union 算法
SELECT * FROM innodb_table
WHERE (key1_part1 = 2 or key1_part1 = 7) or key2_part1 = 4
SELECT * FROM innodb_table
WHERE key1_part1 < 10 OR key2_part1 < 20;一个特殊的情况是,index_merge_intersection 情况下,其中有一个条件是主键范围,这个情况主键条件只起到数据过滤的作用,而并不需要将满足该条件的记录取出再做合并,具体条件是:在遍历二级索引取出 rowid 时,判断该 rowid 是否在主键范围内,如果是则保留,否则忽略这个 rowid。
这里,再回到文章开头遇到的问题,即 where 条件包含:普通索引等值 + 主键范围查询 + order by limit,很多情况走单个二级索引要比走索引合并更快。
其主要原因在于:
走索引合并需要将满足二级索引条件的记录都扫描出来。
走单个二级索引,由于 limit 的存在,实际上并不需要扫描满足条件的全部记录,而在获取到满足条件的记录后就停止扫描,因此在一些情况下效果会更好。
这里,实际上 MySQL 在计算成本的时候,先没有考虑 limit 语句,但是成本计算完之后,对于一些场景会有 rechecking_index_usage 的动作,其中有一个 recheck_reason 是:LOW_LIMIT,其判断逻辑是,当 limit 的行数小于表的“扇出”(rows_fetched * filter) 。经过一些逻辑判断是否需要改变执行计划。
recheck index 的代码如下:
扒出一段源码,如下:也就是在满足一些条件的情况下,会重新检查时候可以使用一个索引来完成,其中包括索引合并的情况
if ((tab->type() == JT_ALL || tab->type() == JT_RANGE ||
tab->type() == JT_INDEX_MERGE || tab->type() == JT_INDEX_SCAN) &&
tab->use_quick != QS_RANGE)
{/*
We plan to scan (table/index/range scan).
Check again if we should use an index. We can use an index if:
1a) There is a condition that range optimizer can work on, and
1b) There are non-constant conditions on one or more keys, and
1c) Some of the non-constant fields may have been read
already. This may be the case if this is not the first
table in the join OR this is a subselect with
non-constant conditions referring to an outer table
(dependent subquery)
or,
2a) There are conditions only relying on constants
2b) This is the first non-constant table
2c) There is a limit of rows to read that is lower than
the fanout for this table, predicate filters included
(i.e., the estimated number of rows that will be
produced for this table per row combination of
previous tables)
2d) The query is NOT run with FOUND_ROWS() (because in that
case we have to scan through all rows to count them anyway)
*/
enum { DONT_RECHECK, NOT_FIRST_TABLE, LOW_LIMIT }
recheck_reason= DONT_RECHECK;
assert(tab->const_keys.is_subset(tab->keys()));
const join_type orig_join_type= tab->type();
const QUICK_SELECT_I *const orig_quick= tab->quick();
if (cond && // 1a
(tab->keys() != tab->const_keys) && // 1b
(i > 0 || // 1c
(join->select_lex->master_unit()->item &&
cond->used_tables() & OUTER_REF_TABLE_BIT)))
recheck_reason= NOT_FIRST_TABLE;
else if (!tab->const_keys.is_clear_all() && // 2a
i == join->const_tables && // 2b
(join->unit->select_limit_cnt <
(tab->position()->rows_fetched *
tab->position()->filter_effect)) && // 2c
!join->calc_found_rows) // 2d
recheck_reason= LOW_LIMIT;
...
if (recheck_reason == LOW_LIMIT)
{
int read_direction= 0;
/*
If the current plan is to use range, then check if the
already selected index provides the order dictated by the
ORDER BY clause.
*/
if (tab->quick() && tab->quick()->index != MAX_KEY)
{
const uint ref_key= tab->quick()->index;
read_direction= test_if_order_by_key(join->order,
tab->table(), ref_key);
/*
If the index provides order there is no need to recheck
index usage; we already know from the former call to
test_quick_select() that a range scan on the chosen
index is cheapest. Note that previous calls to
test_quick_select() did not take order direction
(ASC/DESC) into account, so in case of DESC ordering
we still need to recheck.
*/
if ((read_direction == 1) ||
(read_direction == -1 && tab->quick()->reverse_sorted()))
{
recheck_reason= DONT_RECHECK;
}
}
/*
We do a cost based search for an ordering index here. Do this
only if prefer_ordering_index switch is on or an index is
forced for order by
*/
if (recheck_reason != DONT_RECHECK &&
(tab->table()->force_index_order ||
thd->optimizer_switch_flag(
OPTIMIZER_SWITCH_PREFER_ORDERING_INDEX)))
{
int best_key= -1;
ha_rows select_limit= join->unit->select_limit_cnt;
/* Use index specified in FORCE INDEX FOR ORDER BY, if any. */
if (tab->table()->force_index)
usable_keys.intersect(tab->table()->keys_in_use_for_order_by);
/* Do a cost based search on the indexes that give sort order */
test_if_cheaper_ordering(tab, join->order, tab->table(),
usable_keys, -1, select_limit,
&best_key, &read_direction,
&select_limit);
if (best_key < 0)
recheck_reason= DONT_RECHECK; // No usable keys
else
{
// Only usable_key is the best_key chosen
usable_keys.clear_all();
usable_keys.set_bit(best_key);
interesting_order= (read_direction == -1 ? ORDER::ORDER_DESC :
ORDER::ORDER_ASC);
}
}
} 案例
一个常见的走索引合并反而效率更差的场景:select * from t where c1 ='d' and id>=600000 order by id limit 1000;。
-- 表结构
CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c1` char(64) NOT NULL,
`c2` char(64) NOT NULL,
`c3` char(64) NOT NULL,
`c4` char(64) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_c1` (`c1`)
) ENGINE=InnoDB AUTO_INCREMENT=978914 DEFAULT CHARSET=utf8mb4
-- 涉及到的条件记录
mysql> select count(*) from t where c1='d';
+----------+
| count(*) |
+----------+
| 65536 |
+----------+
1 row in set (0.12 sec)
mysql> select count(*) from t where id>=600000;
+----------+
| count(*) |
+----------+
| 313385 |
+----------+
1 row in set (0.39 sec)
mysql> select count(*) from t where c1 ='d' and id>=600000;
+----------+
| count(*) |
+----------+
| 26112 |
+----------+
1 row in set (0.11 sec)
-- 这里有个注意的地方:实际上不加order by id,返回的记录已经是有序的了,但是执行计划中还是有Using filesort,需要进行额外的排序
mysql> explain select * from t where c1 ='d' and id>=600000 order by id limit 1000;
+----+-------------+-------+------------+-------------+----------------+----------------+---------+------+-------+----------+--------------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------------+----------------+----------------+---------+------+-------+----------+--------------------------------------------------------------+
| 1 | SIMPLE | t | NULL | index_merge | PRIMARY,idx_c1 | idx_c1,PRIMARY | 260,4 | NULL | 26667 | 100.00 | Using intersect(idx_c1,PRIMARY); Using where; Using filesort |
+----+-------------+-------+------------+-------------+----------------+----------------+---------+------+-------+----------+--------------------------------------------------------------+
1 row in set, 1 warning (0.00 sec)
-- 执行时间:170ms
1000 rows in set (0.17 sec)
-- slowlog中可以看到其扫描行数为:27112
# Time: 2024-06-13T19:00:38.741184+08:00
# User@Host: root[root] @ VMS184912 [10.61.250.57] Id: 148
# Query_time: 0.174327 Lock_time: 0.000802 Rows_sent: 1000 Rows_examined: 27112
SET timestamp=1718276438;
select * from t where c1 ='d' and id>=600000 order by id limit 1000;
-- 如果去掉order by语句:10ms,其执行计划仍然是索引合并但是没有了Using filesort
mysql> explain select * from t where c1 ='d' and id>=600000 limit 1000;
+----+-------------+-------+------------+-------------+----------------+----------------+---------+------+-------+----------+----------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------------+----------------+----------------+---------+------+-------+----------+----------------------------------------------+
| 1 | SIMPLE | t | NULL | index_merge | PRIMARY,idx_c1 | idx_c1,PRIMARY | 260,4 | NULL | 26667 | 100.00 | Using intersect(idx_c1,PRIMARY); Using where |
+----+-------------+-------+------------+-------------+----------------+----------------+---------+------+-------+----------+----------------------------------------------+
1 row in set, 1 warning (0.00 sec)
-- 执行时间
1000 rows in set (0.01 sec)
-- slow log内容:这里只有1000行,并不需要读取全部满足二级索引的记录
# Time: 2024-06-13T19:00:59.217427+08:00
# User@Host: root[root] @ VMS184912 [10.61.250.57] Id: 148
# Query_time: 0.010773 Lock_time: 0.000145 Rows_sent: 1000 Rows_examined: 1000
SET timestamp=1718276459;
select * from t where c1 ='d' and id>=600000 limit 1000;
-- 如果原本的sql强制走二级索引
mysql> explain select * from t force index(idx_c1) where c1 ='d' and id>=600000 order by id limit 1000;
+----+-------------+-------+------------+-------+---------------+--------+---------+------+-------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------+---------+------+-------+----------+-----------------------+
| 1 | SIMPLE | t | NULL | range | idx_c1 | idx_c1 | 260 | NULL | 53334 | 100.00 | Using index condition |
+----+-------------+-------+------------+-------+---------------+--------+---------+------+-------+----------+-----------------------+
1 row in set, 1 warning (0.01 sec)
-- 执行时间:10ms
1000 rows in set (0.01 sec)
对于慢日志中row_examinded的解释:
/**
Number of rows read and/or evaluated for a statement. Used for
slow log reporting.
An examined row is defined as a row that is read and/or evaluated
according to a statement condition, including in
create_sort_index(). Rows may be counted more than once, e.g., a
statement including ORDER BY could possibly evaluate the row in
filesort() before reading it for e.g. update.
*/针对这种情况的优化:
评估是否需要 order by 语句,在使用二级索引的一些情况下(如本例中),返回的结果本身已经是按主键顺序显示,则可省略 order by 语句。
注意:这种方式和使用到的索引有关,如果使用到的二级索引条件不能使主键有序排列则可能返回结果不是有序的,如果业务需要绝对保证顺序,不建议用该方式。
id范围条件改为id+0>=,使 SQL 走二级索引,一些情况可能需要再 order by 的id条件上加id+0,根据实际需要评估。
总结
通常情况下对于一张表的访问,MySQL 选择一个索引,在 where 条件中 range condition 满足下面条件的情况下,有可能使用到两个索引,即索引合并:
二级索引的条件满足:where 条件需要有所有的索引字段,且是等值匹配。例如一个索引
idx(a,b,c),则使用该索引的 where 条件需要是:a=? and b=? and c=?主键范围查询。

天启
62 天前