[分享]GO-1:智元机器人发布的通用具身基座大模型
GO1是什么?GO1是智元机器人发布的通用具身基座大模型,采用ViLLA架构,结合视觉、语言、隐式动作和执行能力。它通过学习人类视频和少量样本泛化新任务,支持多机器人形态并持续进化。GO1代表了具身智...
GO-1是什么?
GO-1是智元机器人发布的通用具身基座大模型,采用ViLLA架构,结合视觉、语言、隐式动作和执行能力。它通过学习人类视频和少量样本泛化新任务,支持多机器人形态并持续进化。GO-1代表了具身智能向通用化、智能化发展的新阶段,预示着机器人将具备更广泛的应用潜力。
GO-1的主要特点
ViLLA架构:GO-1采用Vision-Language-Latent-Action (ViLLA)架构,通过预测隐式动作标记,连接图像-文本输入与机器人动作执行。
多模态学习能力:利用海量互联网图文数据,GO-1的VLM组件具备通用场景感知和语言理解能力。
隐式规划与动作执行:MoE中的Latent Planner和Action Expert分别负责动作理解和精细执行,增强了模型的泛化和执行能力。
人类视频学习:GO-1大模型可以结合互联网视频和真实人类示范进行学习,增强模型对人类行为的理解,更好地为人类服务。
小样本快速泛化:GO-1大模型具有强大的泛化能力,能够在极少数据甚至零样本下泛化到新场景、新任务,降低了具身模型的使用门槛,使得后训练成本非常低。
一脑多形:GO-1大模型是通用机器人策略模型,能够在不同机器人形态之间迁移,快速适配到不同本体,群体升智。
持续进化:GO-1大模型搭配智元一整套数据回流系统,可以从实际执行遇到的问题数据中持续进化学习,越用越聪明。
GO-1的模型表现
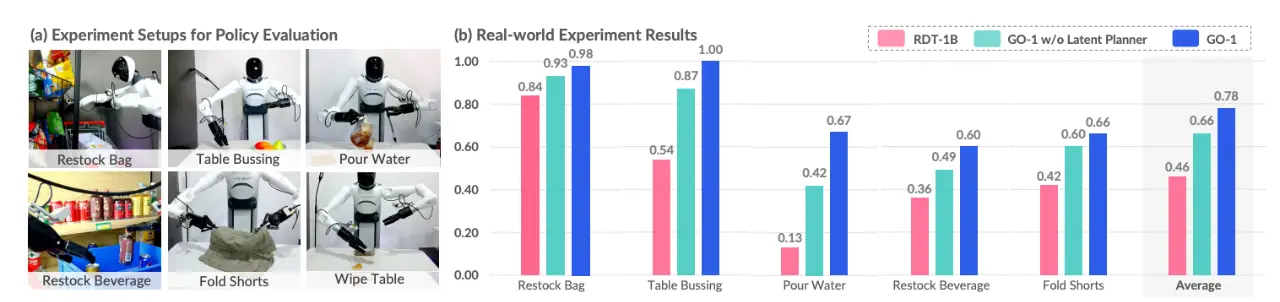
智元在五种不同复杂度的任务上测试 GO-1,结果显示,相比已有的最优模型,GO-1 的平均成功率提高了 32% (46% -> 78%)! 尤其在 “倒水”、“清理桌面” 和 “补充饮料” 等任务上,表现尤为突出。
- 香港、美国站群服务器、云服务器、大带宽、自营机房,线路稳定。
- w3c标准是什么
- VS Code快捷键大全
- pin码是什么意思
- 为什么音量设置最大是100,却还有许多音量增强300%的插件?
- PHP的命令行扩展Readline相关函数学习
- Trae 支持哪些编程语言?
- 通义灵码
- 发现有一句至理名言不错
- PHP的Mcrypt加密扩展知识了解
- PHP的另一个高效缓存扩展:Yac
- 人工智能安全(AI Security)
- 在PHP中操作临时文件
- 生成模型(Generative Models)
- 强化学习中的探索与利用(Exploration vs. Exploitation)
- PHP的加密伪随机数生成器的使用
- 学习PHP弱引用的知识
- 判别模型(Discriminative Models)
- Agent智能体如何学习新技能?
- use关键字在PHP中的几种用法
- 逻辑回归(Logistic Regression)
- 通义千问-Max (qwen-MAX)
- 接入deepseek的平台有哪些
- 付高额彩礼还是提出分手,唉
- seyouCMS程序需租用站群服务器的优势
- PHP中操作数据库的预处理语句
- LINUX下用PHP获取CPU型号、内存占用、硬盘占用等信息代码
- 站群服务器怎么做跨境电商店群
- 在PHP中如何为匿名函数指定this?
- 跨境电商店群租用美国站群服务器



